
Mistral AI is stacking experts
Mistral AI is stacking experts
A speculative post on Mistral-Medium's architecture, and what Mistral-Large might look like

A bit over a month ago, Mistral AI came out with two new models that quickly made news – Mixtral 8x7B, a fully open-source Mixture-of-Experts (MoE) model, and a proprietary Mistral-Medium model, only available through their currently restricted APIs.
Preliminary results are promising. On open-source benchmarks, 8x7B appears to narrowly surpass GPT-3.5 and Llama-2 70B. Little else is known. The blog post, like the paper, is sparse on details, as is common nowadays in industry. It is more marketing copy than a research paper. Even less is known about Mistral-Medium.
In this article, I would like to make the case for why I think that Mistral-Medium is just a Mixtral model with more than 8 experts, and why I think it is likely that a future Mistral-Large will follow the same pattern.
Mixture-of-Experts background
Mixture-of-Expert (MoE) models, like its ancestor Transformer architecture it builds on, were invented at Google. Although the concept of experts have been used outside of deep learning for decades, Google really pushed the frontiers of expert feed-forward layers in Transformers at extremely large scales.
That MoE would be developed at Google was in many ways inevitable – back in 2017 around the time that Transformers were invented, Shazeer et al. were playing with large MoE style layers in LSTMs, the architecture-of-choice at the time. Progress at first was slow (by AI standards) – causal self-supervised pre-training was introduced by OpenAI in their first GPT paper a year later, and MoE transformer layers were not explored until 2020, when Shazeer and company came out with GShard.

GShard was an outrageously large model at the time, spanning 600 billion parameters split over 2048 experts. Most of the paper talks about the infrastructure that Google had to build to support this kind of training run. It also introduced many of the core concepts still used in MoE Transformers today, such as expert capacity and token overflow, i.e. how to deal with experts that are routed too many tokens at once.
Half a year later, Shazeer, Fedus, and Zoph introduced the Switch Transformer, where they scale encoder-decoder Transformers to an even more ridiculous 1.6 trillion parameters and 2048 experts (named Switch-C). They found that scaling the number of experts was a very simple way to significantly improve performance, at the cost of even greater complications in training infrastructure and numerical stability.

The Switch layer, as they named it, differentiates itself from the one used in GShard and the GLaM paper that followed it by only routing each token to a single expert, versus the k > 1 (often set to 2) experts that were more common. k > 1 experts were thought to be necessary for training stability, though the Switch paper argued it was not.
Almost one year after the Switch paper, Google comes out with GLaM (Generalist Language Model), the first GPT-3 style decoder-only Transformer with MoE layers, which they scaled up to 1.2 trillion parameters and 64 experts and trained on 1.6 trillion tokens. At this point, MoE architectures seem to stabilize, as everyone aligns on the same model: alternate MoE and regular feed-forward layers, route to k = 2 experts at each layer, a load balancing auxiliary loss, etc.
As with Switch-C, GLaM shows that MoE allows Transformers to perform dramatically better – for a fixed data size and sufficiently large number of experts, it consumes less compute but performs even better. In particular, it appears that increasing the number of experts continues to work well beyond 8 or even 64 experts.
Mistral AI loves Mixture-of-Experts
Mixtral-8x7B is very clearly inspired by GLaM: the CEO came from DeepMind, the other employees were mostly from Meta AI which barely did any MoE research, they use k = 2 experts, with outputs weighed by the softmax score of the gating layer, and explicitly call out the GShard paper (but not Switch or GLaM surprisingly).
The question is then: why did they stop at 8 experts? GShard and Switch scaled up to 2048 experts, GLaM up to 64 (but with dramatically bigger experts, equivalent to 64B parameter dense Transformers). My answer to this is (1) 8 experts produces a sufficiently small model (47B parameters) that it can be open sourced and used by the community, while still producing a big enough performance gain to top the leaderboards, including surpassing GPT-3.5 and Llama 2 70B, and (2) they didn’t.
Mistral-Medium came out around the same time as Mixtral-8x7B. They have somewhere around 20 full-time employees. It is solidly but incrementally better than Mistral-Small (the 8x7B model). The far likeliest explanation is that they reused the same stack to train a smaller model that they open sourced and a larger one for proprietary purposes.
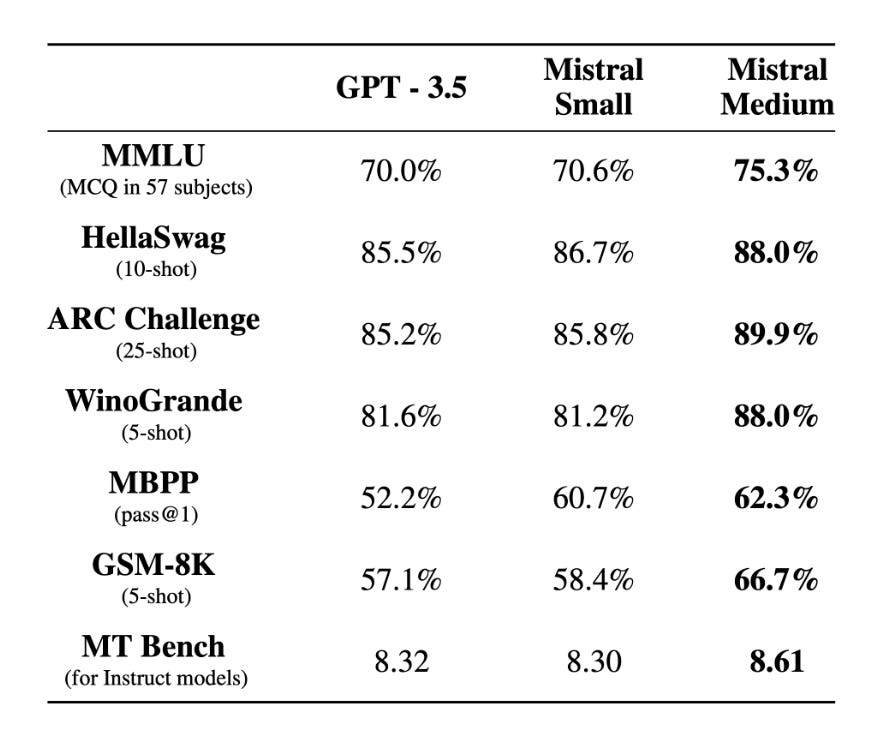
My guess is that Mistral-Medium is equivalent to Mixtral-64x7B. Although it is possible that they increased the size of the base model, the difference in performance is not big enough for me to suspect it, and the ease with which they could increase the number of experts seems like the most reasonable explanation for why Mistral-Medium came out so shortly after Mixtral-8x7B. Instead, I think that the naming of Mistral-Medium, along with their recent $400M raise, indicates that they are planning on training a much bigger MoE model.
If they do, the architecture will probably remain the same, just with more and bigger experts. Something on the same scale as GLaM (64 experts each corresponding to a 64B base model) wouldn’t be surprising, in which case the parameter count (1-2T) would be comparable to that of GPT-4. Considering that GPT-4 was trained back in 2022, and given the quality of models that Mistral AI has been able to output given significantly fewer resources, we shouldn’t be surprised to see Mistral-Large match or even surpass GPT-4.