
The road to AGI
The road to AGI
My take on AGI timeline speculation

Recent progress in AI has brought about a resurgence of conversations on the topic of AGI. While this has been incredibly exciting, my impression so far has been that there is far more speculation than is justified given the minimal effort that has gone into analyzing how our current AI models work and what our plan is for getting from where we are now to AGI.
In this article, I hope to contribute to the conversation by sharing my thoughts on what I think it might take for us to go from current LLMs to true AGI and how far away I think we are. This is not a rigorous research paper, so I will cite sources and justify my stance inconsistently. Please treat this as an opinion piece. If you are strapped for time, feel free to skip to the end of the essay to see my AGI predictions.
Overview
The article contains the following sections:
A definition of AGI
History of AI
Survey of recent research
Ideas for how to get to AGI
AGI timeline
Predictions & takes
Let’s get started.
Defining AGI
Step 1: from tasks to learning
The most common way we measure AGI progress is by picking a task that we humans believe requires “intelligence” and measuring AI performance relative to human experts. Examples include chess, Go, language translation, Turing test, etc.
The problem with this approach, as famous individuals much smarter than me have observed, is that this never leaves doubters satisfied. They can always find another goalpost, and to be honest I believe that this is the correct way to respond. It is far easier to design a system that handles a single task well than to design a system that can generalize. By picking a specific task, we allow for overfitting and diminish its value as a metric for progress (Goodhart's law).
Well-known AI researcher Francois Chollet proposed a solution that I am generally satisfied by in his paper On the Measure of Intelligence – we should study a system’s ability to learn new skills, not just its fixed performance on some set of skills. Although his benchmark proposal ARC feels insufficient for this purpose, it has inspired me to propose the following AGI definition:
An AGI is capable of learning any cognitive skill at the same level and speed as an expert human.
A few examples:
For board games such as Chess and Go, it should be able to receive as input nothing but the rulebook, and within a few years learn to play better than the world champion.
It should be able to learn to perform any cognitive jobs from software development to accounting and digital design.
If asked to design and train an AGI that performs equally or better than itself across all reasonable tasks, it should be able to do so in less time than it would take an AI research team (i.e. on the order of months).
There is one more aspect to the definition above that I want to discuss.
Step 2: consciousness
Most discussions on AGI today implicitly assume that an AGI will be conscious, which I find a bit odd, although I ultimately agree that a sufficiently intelligent AGI probably will have to be conscious.
After all, if an AGI needs to be able to do everything that humans can do, then it also needs to be able to reproduce, contemplate the meaning of life, and feel and express pain when suffering damage. If an AI were to have all of the above and could communicate its thoughts and personal experiences, then at that point I would be fine with treating it as a conscious being.
Consciousness is also useful for some tasks. If we eventually want to assign AI missions with extremely long time horizons such as space exploration then we probably want models that are aware of their own well-being and are capable of self-repair and reproduction.
With that, let’s move on to some history.
Some AI history
A couple of key discoveries from the past century:
1936: Alan Turing publishes “On Computable Numbers, with an Application to the Entscheidungsproblem”, proposing the idea of a universal machine that could simulate any other machine, laying the theoretical foundations for modern computing and AI.
1950: Alan Turing introduces the Turing Test.
1956: John McCarthy, Marvin Minsky, Nathaniel Rochester, and Claude Shannon organize the Dartmouth Conference, often considered the birth of AI as a field.
1959: Arthur Samuel develops a checkers-playing program that uses machine learning to improve its performance over time.
1966: Joseph Weizenbaum develops ELIZA, an early NLP system that uses simple pattern recognition and scripted responses to mimic a psychotherapist.
1976: Edward Feigenbaum and his team develop the expert system MYCIN, which uses a rule-based approach to diagnose blood infections.
1997: IBM's Deep Blue defeats world chess champion Garry Kasparov in a six-game match.
2012: Geoffrey Hinton and his team publish the AlexNet paper, achieving breakthrough performance on the ImageNet task.
2016: DeepMind’s AlphaGo becomes the first computer program to defeat a world champion at the game of Go.
2020: OpenAI’s GPT-3 demonstrates the ability to generate human-like language and perform a range of language tasks.
This history shows that we have made consistent progress, but that progress takes time. In each era, people have made predictions about the imminence of AGI, and so far have been incorrect. To reflect on why this has been the case, here are a few reasons for why I think we have done a poor job of predicting AI progress from past developments:
We tend to make optimistic predictions shortly after big breakthroughs, and pessimistic predictions after long periods of time without breakthroughs. My impression is that this happens because we over-adjust our probabilistic priors when there is recent progress and assume that subsequent progress will come easily. In reality, each development – computers, mathematical optimization, the internet, deep learning, GPUs, etc. – is a necessary step up the staircase towards AGI, and the time between steps appears to be distributed with a magnitude on the order of years or decades.
Why does it take so long between steps? Each step solves very different problems, so progress in one area does not by default result in progress elsewhere. Additionally, I think humans are quite bad at predicting what the next step is. For example, deep learning was dismissed for a great deal of time, and expert systems received a ton of attention a few decades ago but now seems like a dead end on the path towards AGI. It is possible that deep learning will take us straight to AGI within the next few years, but it is also possible that it is yet another dead end.
We get mislead by cool applications. This is true for Deep Blue, Watson, AlphaGo, and ChatGPT. Don’t get me wrong – these applications are incredibly valuable as they allow us to limit test our research, provide tangible benchmarks for us to evaluate progress against, and tell an inspirational story which attracts further investment of resources and talent. However, it is much easier to hack together a system that appears intelligent than it is to build something fundamentally intelligent. See Watson as an example.
A lot of time is spent waiting – waiting for adoption, better infrastructure, better tools, bigger scale, etc. Revolutionary ideas are often not novel by the time that they become revolutionary.
Next, let’s move on from historical context and look at state-of-the-art AI research today.
Survey of recent research
There is far too much to cover, so I will approach this section with a “quality over quantity” mindset. I will pick a few papers that I believe are most representative of the state of AI research today, and dig into them more thoroughly.
The first paper I want to cover is Yann Lecun’s A Path Towards Autonomous Machine Intelligence. It is an ambitious paper by a legendary figure that lays out a proposal for how to get to AGI, and it was also the paper that inspired me to write this blog post.
The two main contributions in his paper are:
A cognitive architecture for AGI.
A new model architecture called JEPA and associated training paradigm that implements the most difficult component of this architecture.
Let’s break them down.
The cognitive architecture
To start, Lecun lays out the “cognitive architecture” of the AGI neural network that he plans to implement and describes the purpose of and interactions between the various components.

The components depicted are as follows:
The agent observes the world through Perception, which processes information-rich data, denoises it, and compresses it for downstream use.
This information is fed to World Model, which holds an intrinsic representation of the external world. This component predicts world states – either missing information from the past and present, or unknown future states.
The world state is fed to Cost (also sometimes referred to as Reward) which determines how good or bad the world state is relative to the agent’s goals.
Short-Term Memory tracks past states and the associated costs that the agent experienced. This is useful for training World Model and Cost.
The Actor takes world states and an implicit goal as determined by Cost and generates actions for the agent to take next in order to achieve its goals.
The Configurator orchestrates all of this by deciding on goals, invoking the Actor and World Model to simulate various strategies and their outcomes, invoking Cost to determine how good strategies are, and then implements its strategy by directing each of the subcomponents.
Why these components specifically? Well, Lecun displays the power of his proposed architecture by demonstrating a variety of ways that these components can interact in order to simulate behaviors common in humans. A few examples:
Reactive behavior: Perception can observe something of danger, World Model can predict that severe harm may affect the agent, Cost may determine that this is extremely bad, and Actor can choose an action to avoid the bad outcome.
Planning: Configurator can decide that a goal is sufficiently complex to require a plan. To plan a strategy, it creates a loop between Cost, Actor, and World Model that simulates various strategies and their outcomes, and halts once it finds a strategy that results in sufficiently low cost (i.e. a strategy that achieves the Configurators goal).
Skill acquisition: The planning behavior described above is very costly, and is not how humans perform tasks. Instead, we learn skills by repeating them, exploring various alterations of our behavior, and taking note of what works. This can be done in our architecture as follows: in order to learn how to solve a new task we can utilize Actor to brainstorm a bunch of approaches, and a mix of World Model and real world interactions to see how they turn out. We can then train Cost to gain an “intuition” for strategies that work well, and Actor to output more of whichever strategies work best.
As you can see, this architecture is quite powerful. Next, let’s look at Lecun’s proposed implementation.
The JEPA architecture
The Joint-Embedding Predictive Architecture (JEPA) is the model Lecun proposes for implementing World Model. It is an Energy-Based Model (EBM) trained using Self-Supervised Learning (SSL) just like current Transformer models like GPT-3 and 4. Key differences is that it explicitly models uncertainty through a latent variable z and predicts latent variables as opposed to real world inputs. He also proposes H-JEPA, a hierarchical version of JEPA, and goes into details about how to train EBMs without suffering from collapse.
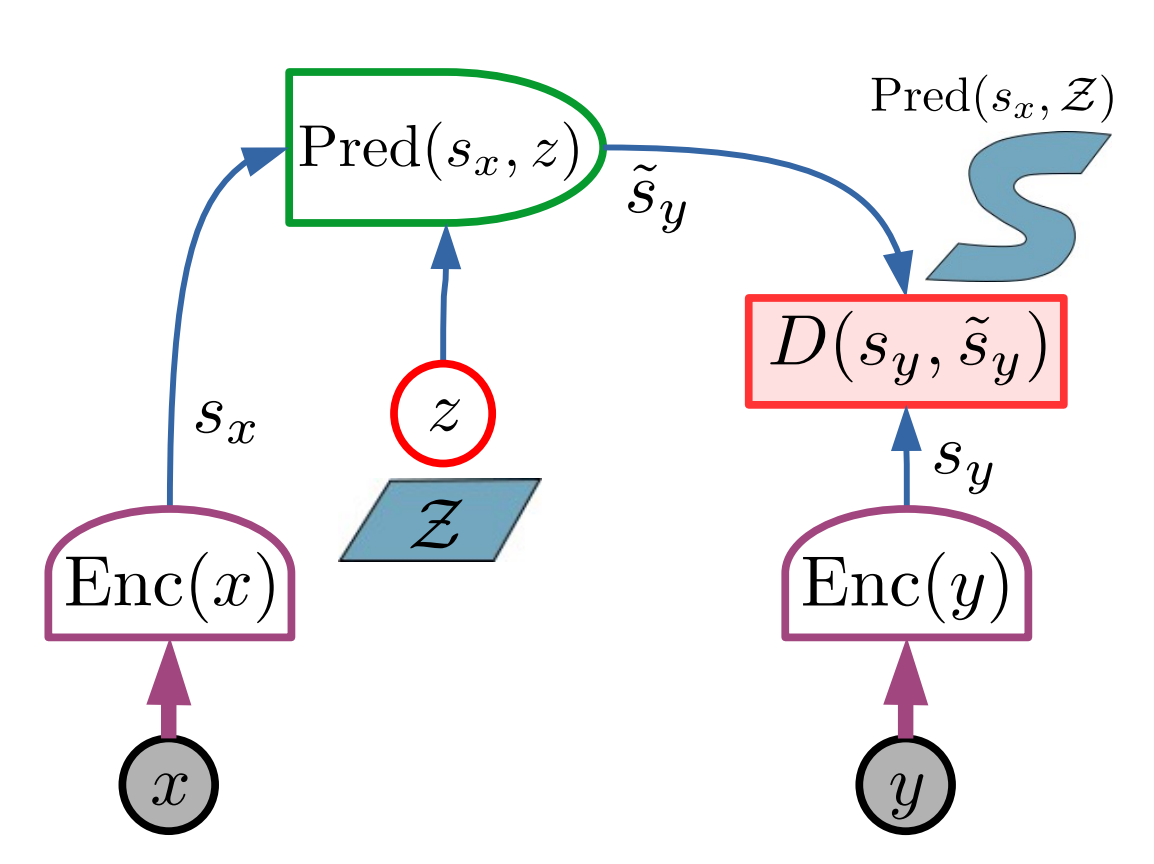
I will not go into more details because JEPA is not going to be used in the rest of this blog post. In my opinion, this architecture is one of the weaker parts of Lecun’s paper. EBMs are out of fashion and simpler approaches appear to do better at multi-modal world modeling. The fact that neither DeepMind nor OpenAI have published any significant RL research using EBMs should speak for itself.
Aside from JEPA, the biggest weakness of Lecun’s paper is how little attention Configurator receives. A lot of the tasks that Lecun expects it to handle are incredibly difficult research problems that the RL space has spent decades trying to solve. Lecun spends about 2 pages discussing the implementation briefly, and his proposal feels inadequate, so we will have to come up with our own.
Next, let’s look at the SotA of multi-modal models.
Multi-modality
There are a bunch of multi-modal models and research approaches, but the one that I feel best aligns with our AGI goals would be A Generalist Agent published by DeepMind in November last year. My summary of the paper is as follows:
Introduces the model Gato which, I quote, “can play Atari, caption images, chat, stack blocks with a real robot arm and much more, deciding based on its context whether to output text, joint torques, button presses, or other tokens.”
Their approach consists of converting all input modalities into a sequence of tokens and then running self-supervised learning on a decoder-only LLM.
Their largest model is only 1.2B parameters. They fit some basic scaling laws and show that scaling helps (as expected), and find no signs of performance saturation. This means that there is room to grow.
For now, performance is good but not insane. It matches single-task models from other papers which, along with its ablation studies, seem to suggest that a single model is capable of learning multiple tasks across modalities, but it is not necessarily benefiting from it.
Context window size is a bottleneck for many tasks. If there is any one argument for why we need to move past Transformers, it would be this.
Summary: this paper shows that it is possible today to extend Transformers to multiple modalities with good performance by simply expanding the set of tokens from language to additionally include vision and robotics. The model can be prompted to complete specific tasks which is awesome, but this ability is severely limited due to context size. The main limitation of this paper (in the context of our goal of building AGI) is that the model has no mechanism through which it can learn new abilities without human supervision.
Next, let’s look over some relevant work from the field of reinforcement learning. We will start by going over the best model-based RL agent that we know of today, which in this case is DreamerV3, introduced in Mastering Diverse Domains through World Models, yet another DeepMind paper. Notes for this paper:
An incredible paper that really pushes the boundaries of (world-)model-based reinforcement learning, which is a very challenging field of research. This RL agent is able to learn from scratch in a ton of different environments, and is the first agent capable of figuring out how to mine diamonds in Minecraft without human demonstrations.
Within the context of Lecun’s brain-based AGI model, DreamerV3 implements Perception, World Model, Actor, and Cost. They opt for an RNN based world model as opposed to a Transformer based one, taking a latent representation of the visual input generated using an autoencoder.
Scaling laws fitted on models ranging from 8M to 200M parameters suggest that there is room to grow.
It’s biggest weaknesses are exploration and subgoal creation. It is outmatched by even simple exploration-based approaches such a Bootstrap DQN, and for long time horizon tasks such as Minecraft the researchers had to add a bunch of hacks such as making mining significantly faster (the agent was too impatient to learn to consistently mine blocks), and giving it explicit rewards when accomplishing subgoals such as building a pickaxe.
Summary: this paper shows that it is possible to build a world-model based RL agent which learns in arbitrary environments with fixed hyperparameters. Comparing DreamerV3 to Gato, one challenging design choice appears: do you use a Transformer based or RNN based world model?
Lastly, let’s quickly cover a few papers on reinforcement learning and other tools that will be relevant later on:
Curiosity-driven Exploration by Self-supervised Prediction – a Berkeley paper that introduces a curiosity-based reward function which motivates RL agents to explore environments by seeking out states that its intrinsic world model struggles to predict.
Hierarchical Deep Reinforcement Learning: Integrating Temporal Abstraction and Intrinsic Motivation - an MIT paper that introduces a new hierarchical RL framework where the top-level agent learns via intrinsic exploration-based rewards and assigns subgoals to lower-level agents.
ReAct: Synergizing Reasoning and Acting in Language Models - a Google and Princeton paper that trains an agent to complete tasks without any RL. They do this by fine-tuning a massive LLM (PaLM, Google’s state-of-the-art model) to break down tasks into smaller steps using chain-of-thought and then take actions to complete the task by accessing external APIs such as search.
Apprenticeship Learning via Inverse Reinforcement Learning - an old but valuable Stanford paper that frames apprenticeship learning (an RL agent wants to learn how to complete a task from a small set of expert demonstrations) as an inverse reinforcement learning (IRL) problem. IRL is the reverse problem that RL tries to solve: rather than trying to learn how to complete a task given a reward function, try to learn what the reward function of an agent is given demonstrations of it taking actions in an environment. More concisely, this paper introduces a key idea for AI alignment: we don’t want to AI to learn to imitate us; we want it to learn what it is that we want, and then go do whatever’s required to accomplish that.
With this background research covered, let’s come up with a plan for getting to AGI.
AGI roadmaps
Let’s think of a few roadmaps for tackling the challenge of implementing and training an AGI. Based on my current (admittedly very limited) understanding of the state of research, I see three pathways:
LLM first
RL first
Moonshot
Let’s go over each of them.
LLM first AGI roadmap
This is actually the approach I feel least confident in. Although LLMs have taken us incredibly far, there are a couple of reasons I think we will have to move past them to get to AGI:
Limited context window. Despite many attempts at getting around the O(n^2) attention scaling in Transformers, no one has properly solved this problem so far. Finite context windows are really problematic, and I don’t see a way around them that doesn’t require a massive redesign of our current Transformer models.
Lack of internal representation. We have found a hacky way to get Transformers to “think” by “writing out loud”. The problem here is that language is limited. It is a poor medium for presenting anything physical, visual, and logical (e.g. uncertainty). That said, there are workarounds such as allowing Transformers to generate sequences in latent space and training on more modalities, so I am less worried about this.
Concerns aside, I promised you an AGI roadmap building on LLMs, so let’s try to work around these issues given what we have. If I had to make a bet on an LLM-based AGI architecture, I would start from the following two assumptions:
If we give a sufficiently powerful LLM access to external memory, say read-write to a document database, and fine-tune it to learn how to use it, the LLM can learn to work around it’s limited context window and lack of memory by using this database as a scratchpad for thoughts and memories.
Text-based monologuing is a sufficiently complex internal representation for an LLM to be able to reach AGI-level performance and behavior.
With that, we are ready to create our roadmap.
Architecture
If LLMs are able to get us to AGI, I don’t particularly imagine that we only need modalities beyond language, text, and sound. The best Transformer architecture for covering these modalities that we know of today is the Gato architecture from DeepMind, so that is what we will use.
Data
We will train on text, images, and video collected from the entire internet, and assume that we have access to proprietary data as well. We will also need a ton of human labelers to generate examples for the multiple fine-tuning steps in our training approach.
Training paradigm
As with most useful models today, we train our LLM in several steps:
Self-supervised learning on internet text, images, and video.
Instruction fine-tuning on the usual set of text tasks.
ReAct based instruction fine-tuning to train the model to access an external document database using text based queries to read and write information that it thinks is “useful” for tasks that it needs to complete.
Instruction fine-tuning on humans completing computer tasks, input format is video + keystrokes in text form. In addition to raw video, we include text annotations describing what actions are being taken and why.
Programming based instruction fine-tuning on GitHub pull requests and from docstrings. These tasks will have to be broken down into multiple steps with additional context added by human labelers.
Human dialogue multi-objective RLHF.
RLHF by having humans create tasks for the model via prompting, rewarding / penalizing when necessary, and providing guidance when stuck.
That’s the best I can come up with. If this were to work it would likely be revolutionary. We would have trained a model that completes arbitrary digital tasks, effectively making many humans obsolete. It is not clear that this model would display consciousness, but perhaps with sufficient internal dialogue fine-tuning we can get it to “emerge” as well.
Now, let’s move on to an RL-first AGI roadmap.
RL first AGI roadmap
Whereas the LLM first AGI roadmap centers around architecture, data, and training paradigm, the RL first roadmap focuses more on the AGI definition we laid out at the beginning of this article: to get to AGI, we need to develop skill acquisition.
This means that the key principle for my RL-first AGI strategy is to have the model figure out how to train itself as opposed to have humans describe how it should learn. We will utilize curiosity-based reward-free RL for this, but first, let’s discuss the architecture.
Architecture
This time, I will choose an architecture more closely resembling that of Lecun’s brain-based model and DeepMind’s DreamerV3. This means:
We are getting rid of the Transformer in World Model and replacing it with an RNN. Although RNNs learn slower, they don’t suffer from the bounded context window issue that Transformers suffer from.
We have a separate Perception component consisting of autoencoders for each modality (text, image/video, and sound, as before).
We have an Actor and Cost component trained using standard Actor-Critic methods from RL such as A3C.
The Short-Term Memory component is implemented as a store of previous latent embeddings which we read and write to using continuous signals (something resembling NTMs).
I’m going to propose something a little odd for Configurator – I’m going to use two LLMs for this component. Since we want to use intrinsic rewards to train Configurator, we probably want this to be an Actor-Critic model of some sort. However, we also want it to be able to reason so as to plan, break up goals into subgoals, and coordinate the other components. The only models that can do this today are LLMs, so let’s make both the actor and the critic an LLM.
Training paradigm
For simplicity lets assume that we start from pre-trained LLMs with capabilities resembling those of ChatGPT. We will train our RL AGI on the internet – we allow it to visit websites, videos, etc., and train it auto-regressively on any document it comes across. Configurator is trained on a different objective from Perception and World Model – it has a curiosity-based objective which rewards it for discovering data that the model has not seen before and has a difficult time predicting. We fine tune Configurator ahead of time to be able to navigate the web.
How does Configurator do this using two LLMs? The Actor is prompted to come up with various plans for achieving whatever goals we assign it (the default being a description of the curiosity goal). The Critic is prompted to read the goal and the various plans outputted by actor, reasons about how good they are, and then predict the expected value of each plan. The rest is standard Actor-Critic learning.
The benefit of an LLM based Configurator is that we can prompt it with different intrinsic goals, e.g. to learn specific new skills on the internet, such as solving coding challenges, play online chess, question answering, and any other task for which we can easily determine when the agent has completed a task successfully.
Lastly, let’s briefly discuss AGI moonshots.
Moonshots
I see two scenarios unfolding – either we have all of the puzzle pieces that we need to get to AGI, but are still working on figuring out how to fit them together, or we are missing some crucial pieces. My personal belief is that the latter is more likely, and that we are still very far away from AGI.
There are a couple of reasons this seems more likely:
Historically, we have underestimated how challenging of a problem AGI is.
Historically, we have overestimated new techniques, in particular how far they will carry us before saturating.
Historically, AI research has made progress via more data, more compute, and more general paradigms. The architectures and training approaches being studied today are still incredibly task-specific and feel too rigid for me to imagine that human-like intelligence could emerge.
Models that attempt general learning such as DreamerV3 are much farther from human levels of performance than task specific models such as GPT-3, and so far we don’t have evidence that scaling general agents results in emergent ability type discontinuous improvements.
On the topic of emergence, the entire phenomenon has made us lazy when reasoning about AI progress. We no longer feel the need to explain why we think our current AI models will develop skills that they are currently lacking – after all, they will just “emerge”. In reality, I think it is most likely that some skills will emerge via scaling and some will not.
Although I do feel optimistic that something else will come along, I will not propose a roadmap for moonshots. Predicting the pace of future research is hard enough – trying to predict the research approaches most likely to work in the long-term is crazy.
That said, here are some fields of research I feel particularly excited about in the context of AGI:
Reinforcement learning without goals. Humans struggle with finding intrinsic purpose. One of the most amazing accomplishments I could imagine would be to develop an AI that has developed an intrinsic sense of purpose without human interference. Current research is pretty stagnant – the only intrinsic goals being studied are “curiosity” based goals that drive the agent to explore the environment so as to maximize the predictive error in its internal World Model. It feels like there are a lot of other intrinsic goals worth exploring now that we have started developing more powerful base agents such as skill acquisition, self-reproduction, and more.
Teaching AI to “think”. The papers that introduced chain-of-thought prompting and Reason+Act are some of the most exciting that I have read because they demonstrate that the AI that we have today is capable of emitting output that resembles thinking. The value of these skills cannot be understated – if we can train a model to think, then we may be able to train a model to gain skills such as planning, exploration, self-improvement, etc. without having to explicitly build it into the system. It would be interesting to explore whether there are other ways for reasoning to emerge beyond self-supervised learning on the internet.
Synthetic data generation. Most RL papers train agents in simulated environments because it is far more efficient and sufficiently closely resembles the real world. My feeling is that the utilization of non-“real” data is underexplored, in particular within NLP. For example, current LLMs are probably powerful enough to be able to read internet text, propose edits to improve the quality and accuracy of the document, reason about each edit, and opt to keep only the ones that it believes makes the text better with very high confidence. Yann Lecun’s framework around Modes formalizes something similar for a kind of model self-distillation that I think is very promising.
AI + Robotics. If we want AI to be helpful in the physical world, we will need to give it a physical embodiment. Google’s PaLM-E is probably the most impressive result so far, but its a pretty hacky solution, given that PaLM is a text-only model. As we are seeing a shift towards multi-modality across all the big AI labs, I expect this field of research to make exciting progress in the coming years.
Evolutionary approaches. The research that most closely resembles “AI that makes better AI” would be evolutionary approaches. Evolution is a wildcard – research so far has not been particularly impressive, often resulting in incremental changes that lead to modest gains that are outstripped by foundational discoveries such as new architectures or training methodologies. That said, evolution is the only force in the universe that has produced intelligence that we know of, so it seems reasonable that it could do so again. Designing better search mechanisms and simulated environments that sufficiently resemble real world tasks will be necessary to make further progress.
With that, what would I do if I was given a very long time horizon and wanted to develop AGI while maximizing my chances of success? I would probably only change one thing relative to what we are seeing today in the AI space: explore more broadly.
Recent discoveries in LLMs around emergence reveal that our models behave differently at small and large scales. My worry is that some great result awaits in a subfield that we already know of that is going undiscovered due to a lack of resources. For example, although I don’t feel optimistic about Lecun’s beloved energy-based models, it is possible that scaling up EBMs may lead to results that we don’t expect, including performance that surpasses LLMs. Similarly, maybe evolution-based learning or meta learning is the missing key to the AGI puzzle.
If my hunch is true and we are missing some crucial pieces, then there is not much to be done beyond the above. Let’s wait and see what scientists come up with, and let’s revisit the roadmap then.
Timeline predictions
The question is not how long it would take to implement and train a model as described above (not considering the likelihood that the particular roadmap I laid out doesn’t work), but rather how long it would take to tweak and scale it to the point that the resulting model reaches AGI level performance.
Transformers
For the Transformer based approach, my sense is that we could have an incredibly powerful and useful model in the next couple months or years, but that we probably never will get to AGI building on LLMs, for the reasons I’ve described earlier.
In what ways could this prediction be wrong? Well… emergent abilities and the fact that no one really knows how LLMs work and how high of a bar AGI really is. After all, humans aren’t that intelligent, so maybe a big enough Transformer is enough to match us in performance.
Assuming LLMs don’t saturate, I guess I could see a Transformer that is better than the best software engineer and the best AI researcher in the next 4-5 years, and thus perhaps we get to AGI in 7-8 years once we develop better memory access mechanisms and better big project planning and completion capabilities. At that point, we might not need all the other components in Lecun’s proposed model, and if we do then we could just let our LLM figure out how to add them.
That said, even the above does not clearly lead us to intrinsic objectives, sense of self, and creativity. Will we be able to get there with LLMs? I think maybe, but I wouldn’t bet on it in the next 10-20 years, as I am not seeing fundamental research addressing these limitations right now. Historically it has tended to be more common for big breakthroughs to be spread several years apart, so in aggregate 2+ decades seems reasonable if we ever get there.
TLDR: if everything goes perfectly beyond our wildest imagination, then 7-8 years. More likely 20+ years. Most likely is never (with an LLM based approach).
Reinforcement learning
For the RL-based approach, I feel more confident in the architecture and way less confident in the training paradigm. Crawling the internet and training on raw, non-preprocessed data is slow and very information-sparse. Ignoring these details and assuming that the general idea of training a Gato+DreamerV3-Lecun-brain model (let’s just call it RL-AGI for brevity) with intrinsically motivated RL works, I guess I could see a slightly greater chance that we get to AGI.
Again, the most difficult hurdle to pass is making the model good enough to be able to improve itself faster than humans can, and considering that the core of the training paradigm I have proposed is still self-supervised learning on internet data, I worry about the model not being sufficiently creative and principled in its thinking.
So what does the best case scenario look like? Well, suppose that we scale up an RL-AGI to PaLM sizes (~500B parameters) and that this is sufficient for it to develop reasoning capabilities. Further suppose that it can use its language capabilities to learn new skills using its built in reward signal without supervision or text based descriptions. At this stage, we might already have AGI (after all, just think about what LLMs like GPT-3 are capable of which much simpler architectures), and I guess there is a chance that we can build a system around it that conducts AI research of comparable quality to DeepMind. The timeline would depend on how aggressively DeepMind wants to get to AGI, but the absolute best case is probably at the very least 4-5 years away.
More realistically, we are still many breakthroughs away, and they will probably be spread a few years apart, but I can at least imagine an RL-AGI model behaving sentiently once we get there. Based on the progress labs like DeepMind and OpenAI have made over the past 10 years, I would place a very optimistic prediction for AGI at around 10-15 years out. My biggest worry is that our current RL algorithms still are quite inconsistent and progress has been slow, but it is possible that scale will save us just like it did with LLMs.
My baseline prediction is much further out. Consider the following factors:
Historically, AI winters often follow fast progress for a few years to a decade. In this case, I do expect progress to plateau, but perhaps only for a few years this time (after all, the winters since 2012 and onward have been quite warm).
Winters emerge because new technologies follow S-curves and often solve one problem well but not all problems, and there are certainly problems we have not solved.
Progress on these bottleneck problems (in my opinion RL is the most likely solution to the ones I’ve listed) is moving slower than in NLP and do not appear to be improving in S-curve fashion.
The world is bottlenecked on compute and the training time for SotA models is already several months, which makes iteration a lot slower than it was up until recently.
Consider where we were 10 years ago when AlexNet came out and reignited interest in AI. We have come a far way, but we do not have AGI yet. Models are more general and perform way better, but are still task specific. Research into general models (Gato, DreamerV3) reveal that it is possible, but we aren’t seeing compounding advantages from the additional information relative to task-specific models.
I think it will take a very long time before we have an AI that can train a better AI faster than we can. AI research is incredibly difficult, drawing on disciplines across all of science and all of our cognitive capabilities. We don’t just need AI that can write perfect code given instructions, we need AI that can come up with those instructions in the first place.
Putting this all together, I don’t think we will see AGI for another two decades. Making predictions past that point becomes quite difficult, but my best guess is that there is around a 50% chance that I get to see AGI in my lifetime.
This will seem to some like either an optimistic or pessimistic prediction. My reasoning is that we don’t know what it’ll take, and there are lots of big research problems that take decades if not centuries to solve. Regulation can severely slow down progress, countries may be distracted by internal or external events, and other challenges may emerge. That said, technological and scientific progress has been remarkable over the past centuries and decades, it doesn’t seem like it will slow down dramatically in the next century, and looking at where we are today relative to 50 years ago it is clear that AI has made immense progress.
When do I think we will have AGI? Well, each decade since the 1950s or 60s has brought immense but reasonable progress in computing, and helps put progress into perspective. We have probably a couple of steps left to AGI (I’d place the range around 3-6), and we should also allow for some buffer time in case we have to deal with any wars, political instability, or other crises. Even once we get to AGI, I don’t believe that the singularity is likely to be imminent. Computation is a serious research bottleneck, science and AI research is really hard, and there are diminishing returns to intelligence and effort spent. Taking all of this into consideration, my sense is that we probably get to some form of AGI this century, and significantly-better-than-human AGI sometime in the next century, so somewhere between 2100-2200.
TLDR: if you believe in miracles, 4-5 years. Very optimistic scenario is 10-15 years. My default prediction would be before 2100.
Predictions & takes
To wrap up this article, let me summarize my thoughts and leave you with a few predictions & takes.
20 years from now, in 2043, we will look at the state of AI and be amazed by how it has changed society, but the majority of people will still agree that we do not yet have AGI that is capable of building a better version of itself faster than human AI researchers can. Of course AI will assist heavily in new research, but the majority would agree that the AIs wouldn’t be able to conduct full research projects end-to-end. (90% confident)
By 2100 we probably have some form of AI where many people claim it passes our definition of AGI but some will still disagree. (90%)
By 2200, we will have AGI that is significantly better than humans on any task, including researching and creating better AGIs, but I still don’t think this will lead to the singularity. (70%)
If/when we get to AGI, Transformers will be a very small part of the system. The key discoveries that get us there are more likely to be engineering centric (scale of compute and data), and algorithmic (goal-driven learning, planning, new unsupervised learning schemes). Attention will of course stick around, but will be dispersed throughout the system. Attention will not be all that we need. (95%)
Raw LLM performance in research settings will saturate in the next few years (say 3 years), but few people will notice or care. First, we have barely scratched the surface of the applications of these models (fine-tuning, RLHF, interfacing with existing data, chaining, reasoning, etc), and will see incredible progress on the application side for many years to come. Second, we are already starting to see the transition to the next AI S-curves: multi-modal models and the return of recurrent models. (60% confident about LLM saturation)